Java Interview Knowledge Base
1. Java Basics
1.1 What are the data types in Java?
- Primitive types: byte (1), char (2), short (2), int (4), long (8), double (8), float (4), boolean (1)
- Reference types: classes, interfaces, enums, arrays
1.2 Differences between object-oriented and procedural programming?
Both are development paradigms.
- Procedural: Focuses on step-by-step implementation of problem-solving steps.
- Object-oriented: Combines data and methods into objects; systems are composed of these objects.
- Procedural uses functions for faster performance without instantiation but is harder to extend, maintain, and reuse.
- Object-oriented uses classes for modules with higher security, easy extension, reuse, flexibility, and maintainability.
1.3 Relationship among JDK, JRE, JVM
- JVM: Java Virtual Machine; runs Java code and provides cross-platform capability.
- JRE: Java Runtime Environment; includes core libraries and JVM.
- JDK: Java Development Kit; includes tools (e.g., javac) and JRE.
1.4 What is bytecode?
Java source files are compiled into .class bytecode files (binary streams) that JVM can load and execute quickly.
1.5 Characteristics of object-oriented programming?
Three main features: encapsulation, inheritance, polymorphism.
- Encapsulation: Hides internal details and provides access via methods; reduces coupling and increases security.
- Inheritance: Derives new classes from existing ones, reusing and extending functionality.
- Polymorphism: Same behavior can take multiple forms via overloading, overriding, and parent references to child objects.
- Also abstraction: Abstracting real-world objects into code.
1.6 Difference between StringBuilder and StringBuffer?
Both extend AbstractStringBuilder and are mutable. StringBuffer uses synchronized for thread safety; StringBuilder is not thread-safe.
Thread safety means multiple threads operate on an object with correct results.
1.7 Why can’t static methods call non-static methods/variables?
When a class is loaded, static members are initialized first, but non-static members are not yet initialized (no memory). Thus calling them causes errors.
1.8 Exceptions, Error vs Exception, runtime vs checked exceptions?
Java exception hierarchy:
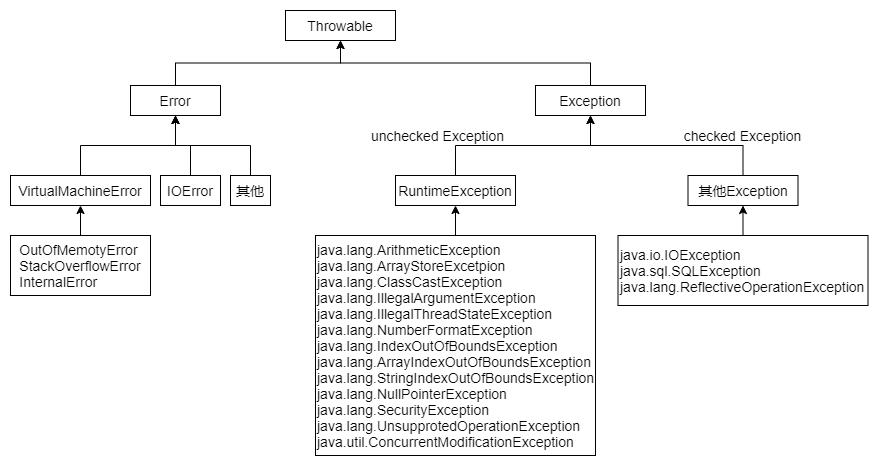
Throwableis the root.Error: Serious issues like resource exhaustion; unrecoverable.Exception: Recoverable; divided intoRuntimeException(unchecked) and other exceptions (checked).- Unchecked: can choose to handle or not.
- Checked: must be caught or declared.
1.9 Java Memory Model (JMM)
JMM is an abstract specification defining how threads interact via shared memory.
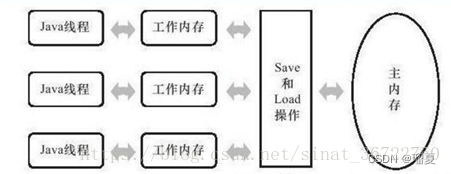
- Main memory: Shared by all threads, stores shared variables.
- Working memory: Thread-private, stores copies of shared variables.
- Threads modify copies and synchronize back to main memory; communication between threads goes through main memory.
JMM guarantees atomicity, visibility, and ordering.
- Atomicity: Operations are indivisible;
synchronizedensures this. - Visibility: Changes by one thread are visible to others;
volatileandsynchronizedensure this.volatile: Forces reads/writes directly to main memory, avoiding thread-local caching.
- Ordering: Instructions are ordered within a thread;
volatileprevents instruction reordering via memory barriers.- Write barrier: After volatile write, changes are flushed to main memory; prevents reordering before the barrier.
- Read barrier: Before volatile read, fetches latest from main memory; prevents reordering after the barrier.
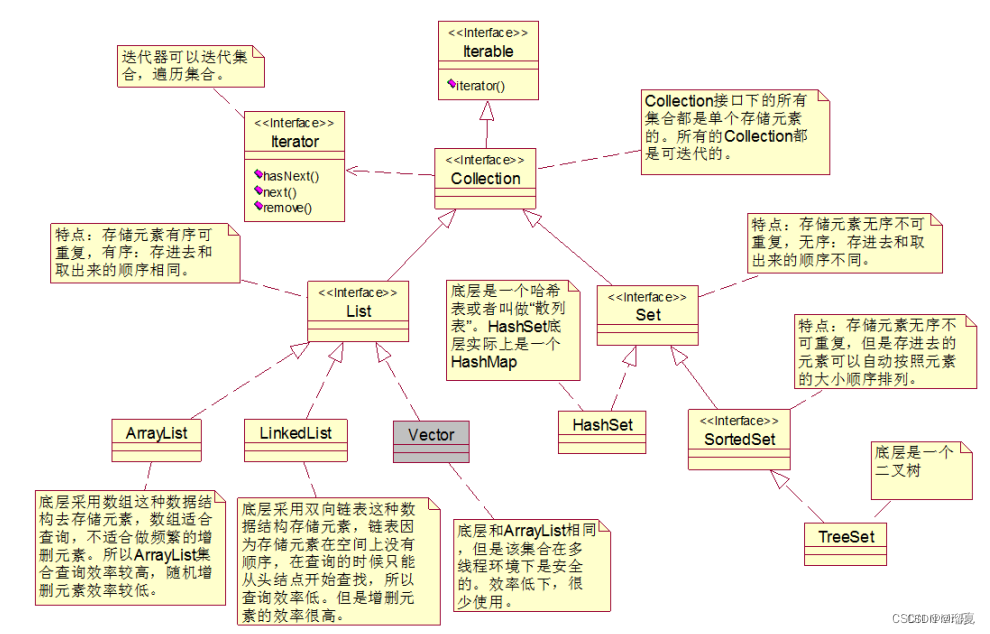
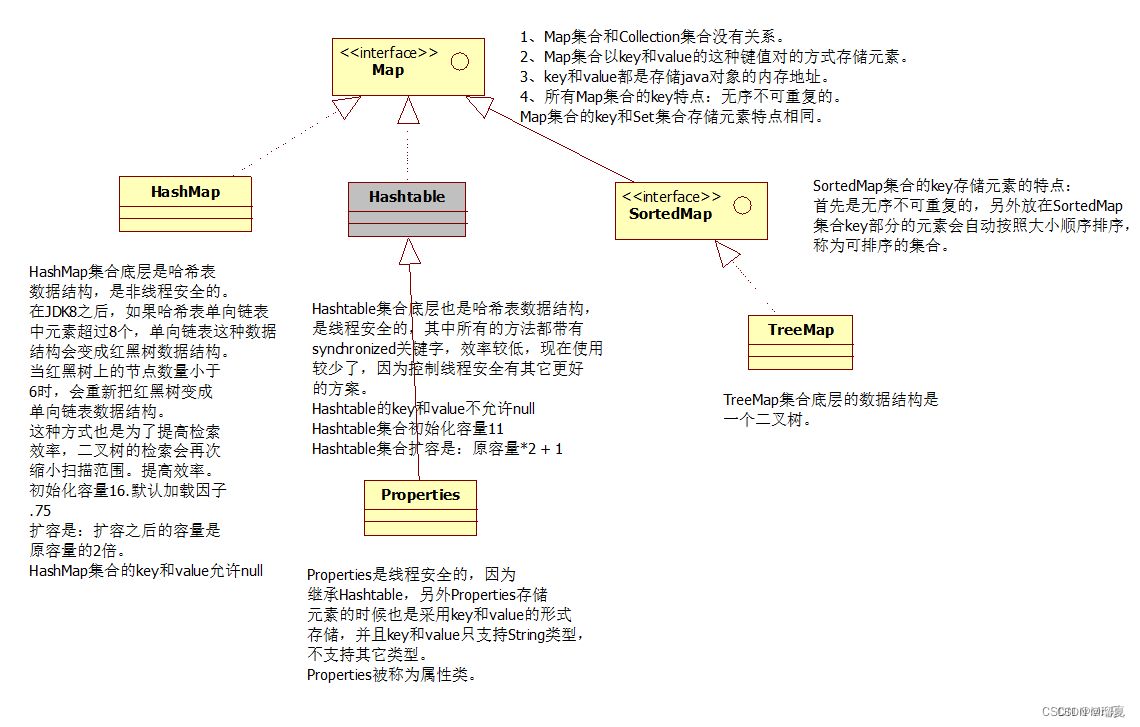
1.10 Common Collections
Java collections are derived from Collection (single column) and Map (two columns).
Collectionsubinterfaces:List,Queue,Set.- List implementations:
ArrayList,Vector(thread-safe),Stack,LinkedList(doubly linked). - Set implementations:
HashSet(backed by HashMap),SortedSet,TreeSet(backed by TreeMap, ordered),LinkedHashSet. - Thread-safe collections:
Vector,Hashtable,ConcurrentHashMap,Stack,ArrayBlockingQueue,ConcurrentLinkedQueue.
1.11 Overriding vs Overloading
- Definition: Overloading: same method name, different parameters. Overriding: subclass overrides parent method.
- Scope: Overloading in one class; overriding between parent and child.
- Polymorphism: Overloading is compile-time; overriding is runtime.
- Return type: Overloading no restriction; overriding must be same or covariant.
- Parameters: Overloading can differ in count, type, order; overriding must match.
- Access modifier: Overloading no restriction; overriding must not reduce access.
1.12 HashMap internals: insertion, resizing
Prerequisites:
- Binary tree: each node has at most two children.
- BST: left subtree ≤ current node ≤ right subtree.
- Red-black tree: self-balancing BST with O(log n) for search, insert, delete.
- Nodes are red or black; root and leaves are black; red node's children are black.
- Leaves are null; all paths from a node to leaves have same number of black nodes.
- Hash table: KV storage using hash function.
HashMap: Array + linked list / red-black tree.
- Inserts: compute key's hash to determine index.
- If same key exists, replace value; else add to list/tree.
- Before JDK 8: array + linked list.
- JDK 8+: array + linked list + red-black tree. When list length > 8, first try to resize array; if array length >= 64, convert to red-black tree.
Insertion (simplified):
- If array is null, call
resize()to create capacity 16. - Compute index:
i = (n - 1) & (h ^ (h >>> 16)). If slot empty, insert new node. - Else check if key exists; if yes, replace value.
- If not, if node is TreeNode, add to tree; else append to list.
- If list length > 8, try to resize if array < 64, else convert to tree.
- After insertion, if size > threshold (capacity * load factor 0.75), resize.
- Resize: rehash elements into new array.
Resizing:
- Called during first initialization or when threshold reached.
- Capacity doubles each time.
- Creates new array, moves old elements.
- For linked list, recalculate indices.
- For red-black tree, add accordingly.
1.13 Object creation methods
new- Implement
Cloneableand callclone() - Reflection:
Student.class.newInstance() - Reflection:
Class.forName("entity.Student").newInstance() - Reflection:
Student.class.getConstructor().newInstance() - Spring container injection
1.14 Four access modifiers
public: accessible from any class.protected: accessible within same package or subclasses.default(no modifier): accessible only within same package.private: accessible only within same class.
2. Multithreading
2.1 Process vs Thread
- Process: A running program; basic unit of system resource allocation; independent memory space.
- Thread: Smaller unit within a process; shares memory and resources; lightweight context switching.
- Coroutine: Lightweight thread managed in user space for lower context switching cost.
Differences:
- Process is an instance of a program; thread is the smallest scheduling unit.
- Process has own memory; threads share memory.
- Processes are independent; threads can affect each other.
- Threads are lighter with lower context switch overhead.
2.2 Concurrency vs Parallelism
- Concurrency: Dealing with multiple tasks at the same time (e.g., threads sharing one CPU).
- Parallelism: Doing multiple tasks at the same time (e.g., 4 CPU cores executing 4 threads).
2.3 Ways to create threads; Runnable vs Callable; run vs start
Creation methods:
- Extend
Threadclass. - Implement
Runnableinterface. - Implement
Callableinterface withFutureTask. - Thread pool (common in projects).
Runnable vs Callable:
Runnable.run()has no return value;Callable.call()returns a value (viaFutureTask).Runnablecannot throw checked exceptions;Callablecan.
run vs start:
start()creates a new thread and callsrun(). Can only be called once.run()contains the code to execute; can be called multiple times.
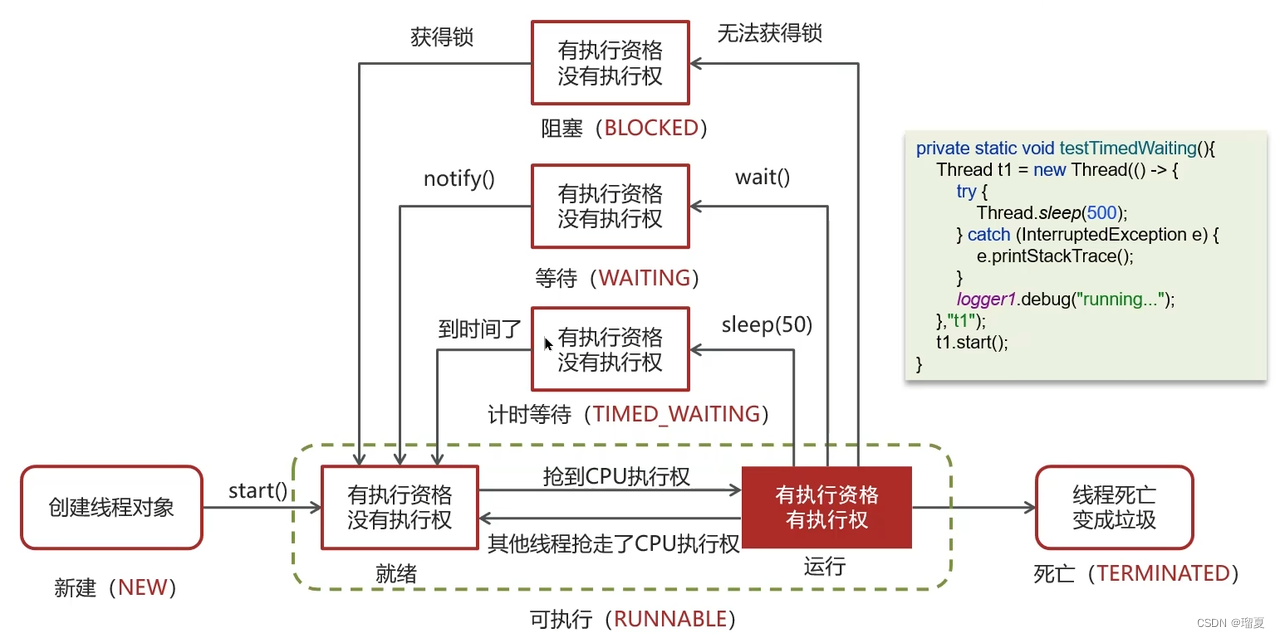
2.4 Thread states and transitions
Six states:
- New: Created but not started.
- Runnable: After
start(), eligible to run. - Blocked: Waiting for a lock.
- Waiting: After
wait()(releases lock). - Timed Waiting: After
sleep(long)orwait(long). - Terminated: Finished execution.
2.5 How to ensure three threads t1, t2, t3 execute sequentially?
Method 1: join()
- Call
t1.join()in t2's run,t2.join()in t3's run.
Method 2: CountDownLatch
- Set initial count. Each thread calls
countDown()when done; main thread callsawait().
2.6 Differences between wait() and sleep()?
wait()is anObjectinstance method;sleep()is aThreadstatic method.wait()must be in a synchronized block with the lock acquired;sleep()does not.wait()releases the lock;sleep()does not release the lock if it holds it.
2.7 Why must wait() and notify() be used within synchronized?
- Programmatically: Otherwise,
IllegalMonitorStateExceptionis thrown. - Thread safety: Without synchronization,
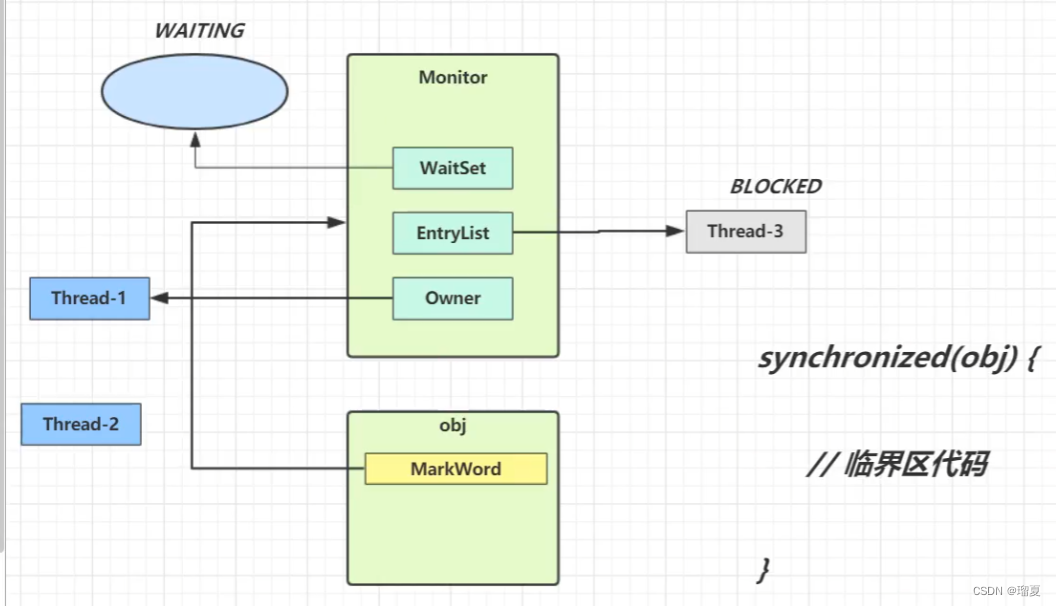
notify()might execute beforewait(), causing a missed wake-up and thread hang. - Internally: Each Java object has a Monitor with
WaitSet,EntryList, andowner.synchronizedsets the owner;wait()moves the thread to WaitSet and clears owner;notify()moves a thread from WaitSet to EntryList. This requires holding the lock.
2.8 synchronized keyword underlying principle
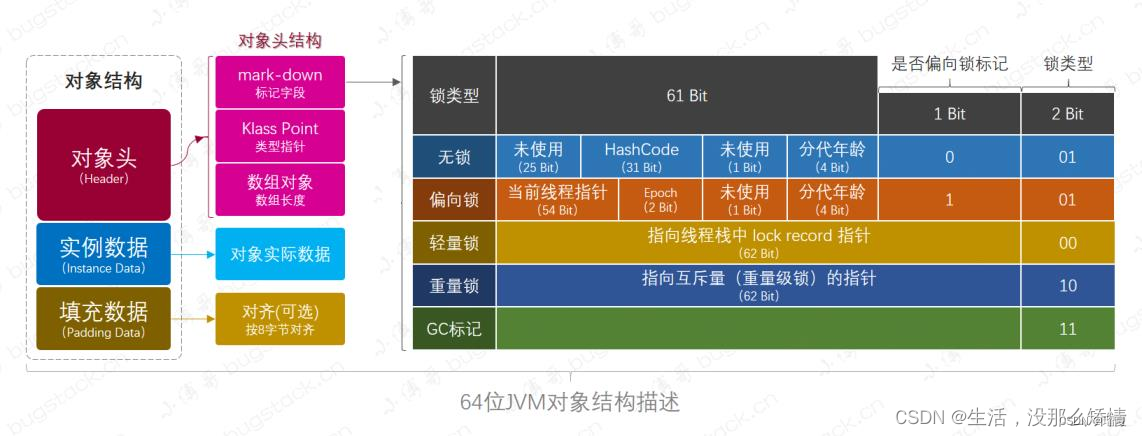
Synchronized uses mutual exclusion. There are three forms:
- Biased lock: Only one thread ever accesses; just records thread ID.
- Lightweight lock: Multiple threads alternate; uses CAS and spin.
- Heavyweight lock: Multiple threads compete; depends on Monitor (JVM object).
Heavyweight lock:
- Monitor has owner, entryset, waitset.
- Thread acquires lock by binding to owner; if occupied, thread enters entryset (blocked).
wait()moves thread to waitset.
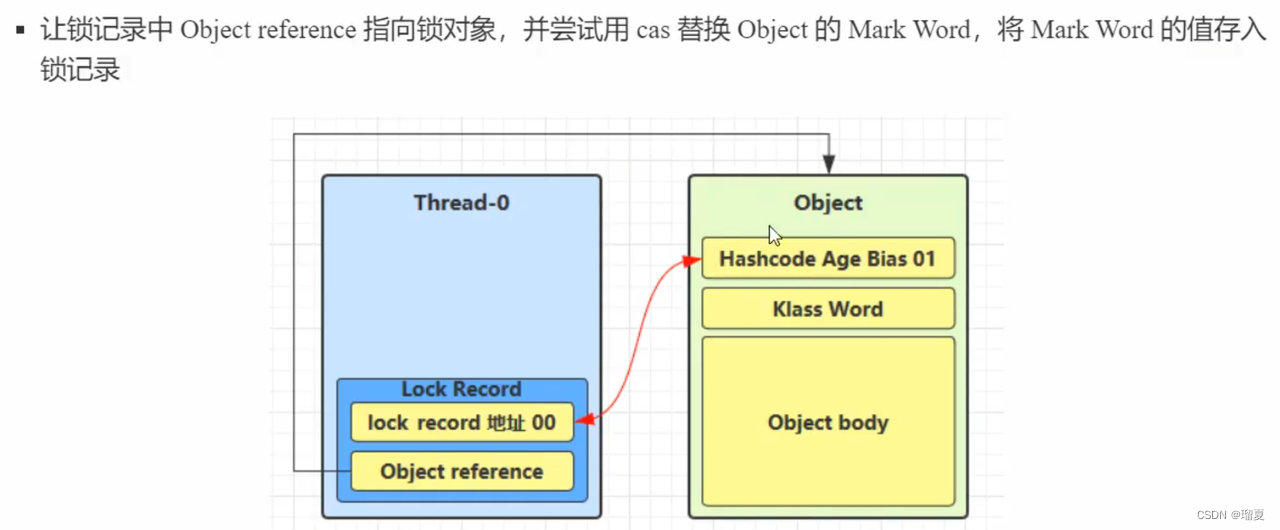
Lightweight lock (no competition):
- No monitor needed. Thread creates a lock record in its stack frame, uses CAS to store lock record address in object header's mark word.
- If CAS fails, either another thread holds the lock (spin then upgrade) or it's reentry (add another lock record with null address).
Biased lock:
- Optimization: Only first CAS sets thread ID; subsequent checks avoid CAS.
2.9 Differences between synchronized and Lock?
- Syntax:
synchronizedis JVM-implemented (C++);Lockis Java API (java.util.concurrent.locks). - Features: Both are pessimistic locks with mutual exclusion, synchronization, and reentrancy.
Lockadditionally supports interruptible waiting (lockInterruptibly()), fairness, timeout (tryLock(time, unit)), and conditional notification (Condition). Lockprovides different implementations likeReentrantReadWriteLock.- Performance:
synchronizedhas biased/lightweight locks good for low contention;Lockoften performs better under high contention with more features.
2.10 What is CAS?
CAS (Compare And Swap) is an optimistic lock approach; guarantees atomicity without locking. Three operands:
- Memory value V
- Old expected value A
- New value B
Only if V equals A, update V to B; otherwise fail. Multiple threads attempting CAS will have only one success; others retry or block.
CAS is a CPU primitive, executing uninterruptibly, ensuring atomicity.
Problems:
- ABA problem: A value changes from A to B and back to A; CAS can't detect.
- Long spinning: High CPU overhead if CAS fails repeatedly.
- Only one variable: Cannot handle multiple shared variables atomically.
2.11 What is AQS?
AQS (AbstractQueuedSynchronizer) is a lock framework used by ReentrantLock, CountDownLatch, etc.
- Maintains a FIFO bidirectional queue for waiting threads.
- Maintains a
state(0 unlocked, 1 locked). - Modifies
statevia CAS for atomicity.
2.12 Principle of ReentrantLock?
ReentrantLock means reentrant lock: same as synchronized regarding reentrancy.
- Based on CAS + AQS. AQS has
stateand a bidirectional queue. - A thread tries to acquire lock via CAS on
state. If success, setsownerThreadto current thread. If fails, adds to queue tail. - Supports fair and unfair modes. Default is unfair; can pass
truefor fair.
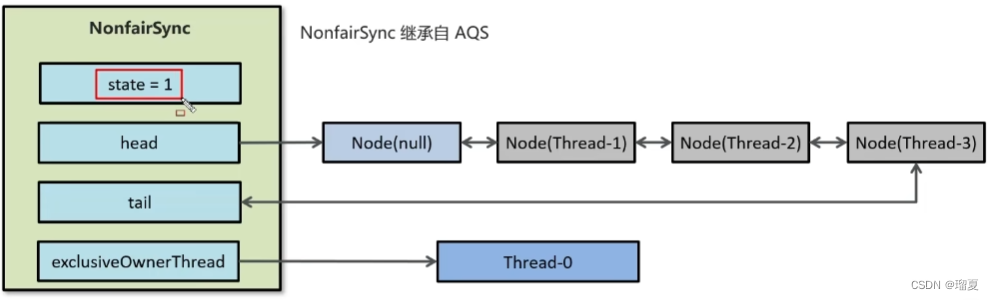
2.13 Pessimistic lock, optimistic lock, distributed lock
Pessimistic lock: Assumes conflict; acquires lock before operation (e.g., synchronized, Lock).
- Suitable for inserts.
- Keep lock granularity small.
- With transactions: commit first, then release lock.
Optimistic lock: Assumes no conflict; checks version before updating (e.g., version field, CAS).
- Suitable for updates.
- Query version first, compare when updating.
Distributed lock: Visible and mutually exclusive across distributed systems. Common implementations: Redis (SETNX), ZooKeeper.
- Issues: accidental lock release due to timeout. Solution: unique value per thread (UUID) and verify when releasing.
2.14 What is deadlock? Conditions and prevention?
Deadlock: A set of threads are blocked forever because each holds a resource the other needs.
Four conditions:
- Mutual exclusion: resources X and Y can only be held by one thread.
- Hold and wait: thread holds one resource while waiting for another.
- No preemption: resources cannot be forcibly taken.
- Circular wait: two threads wait for each other's resources.
Prevention (break conditions):
- Allocate all resources at once (break mutual exclusion).
- Let threads release held resources if allocation fails (break hold-and-wait).
- Request resources in a fixed order and release in reverse order (break circular wait).
2.15 Principle of ConcurrentHashMap?
Built on HashMap; uses CAS + synchronized for thread safety. volatile on Node's next and val ensures visibility.
Insertion:
- Compute hash and locate slot.
- If no hash conflict (slot null), CAS to insert.
- If hash conflict (slot not null),
synchronizedon the head node, then insert.
2.16 Thread pool core parameters and execution principle?
Core parameters (7):
corePoolSize: number of core threads.maximumPoolSize: max threads (core + emergency).keepAliveTime: max idle time for emergency threads.unit: time unit for keepAliveTime.workQueue: queue for tasks when core threads are busy.threadFactory: factory for creating threads.handler: rejection policy when queue is full and max threads reached.

Execution principle:
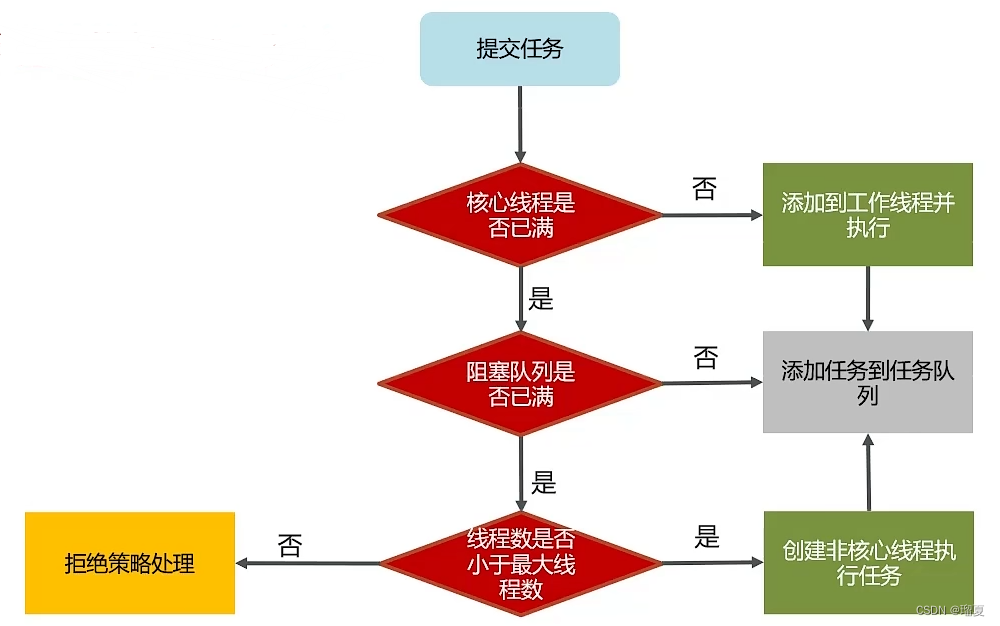
2.17 Common blocking queues for thread pools?
ArrayBlockingQueue: bounded FIFO based on array.LinkedBlockingQueue: optionally bounded FIFO based on linked list.
| Feature | ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|---|
| Underlying | Array | Linked list |
| Bounded | Always bounded | Default unbounded; bounded if capacity set |
| Pre-allocation | Pre-allocates node array | Creates node on insert |
| Locks | Two locks (head and tail) | One lock |
LinkedBlockingQueue supports lock separation for better performance in producer-consumer scenarios with similar rates.
2.18 How to determine core pool size?
No fixed answer; set expected CPU utilization, load, GC frequency, then adjust via testing.
General guidelines:
- High concurrency, short tasks: CPU cores + 1 (reduce context switching).
- Low concurrency, long tasks:
- I/O intensive: CPU cores * 2 + 1 (I/O waits free CPU).
- CPU intensive: CPU cores + 1.
2.19 Types of thread pools?
-
Executors.newFixedThreadPool(int nThreads):- Core = max = nThreads, no emergency threads.
- Unbounded
LinkedBlockingQueue. - Suitable for known number of tasks.
-
Executors.newSingleThreadExecutor():- Core = max = 1.
- Unbounded
LinkedBlockingQueue. - Suitable for sequential execution.
-
Executors.newCachedThreadPool():- Core = 0, max = Integer.MAX_VALUE, keepAlive = 60s.
SynchronousQueue(insert must wait for remove).- Suitable for many short-lived tasks.
-
Executors.newScheduledThreadPool(int corePoolSize):- Core = user-defined, max = Integer.MAX_VALUE.
- Suitable for scheduled tasks.
2.20 Thread pool usage scenarios
-
Batch import from PostgreSQL to Elasticsearch:
- Calculate total rows, page size 200, total pages N. Create
CountDownLatch(N). Create N threads to import; each callscountDown(). Main thread waits for completion.
- Calculate total rows, page size 200, total pages N. Create
-
Asynchronous operations:
- E.g., save search log asynchronously without affecting search.
- Add
@EnableAsyncon SpringBoot app, define thread pool bean, use@Async("poolName")on method.
2.21 ThreadLocal understanding and memory leak
ThreadLocal provides thread-local variables.
- Each
Threadhas aThreadLocalMap(key: ThreadLocal, value: variable). set()gets current thread's map and stores value;get()andremove()work similarly.
Memory leak:
ThreadLocalMap.EntryextendsWeakReference<ThreadLocal>; key is weak reference, value is strong reference.- When garbage collection clears the weak key, the value remains, causing a leak.
- Solution: Call
remove()after use.
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
3. JVM
3.1 Main components of JVM and their roles
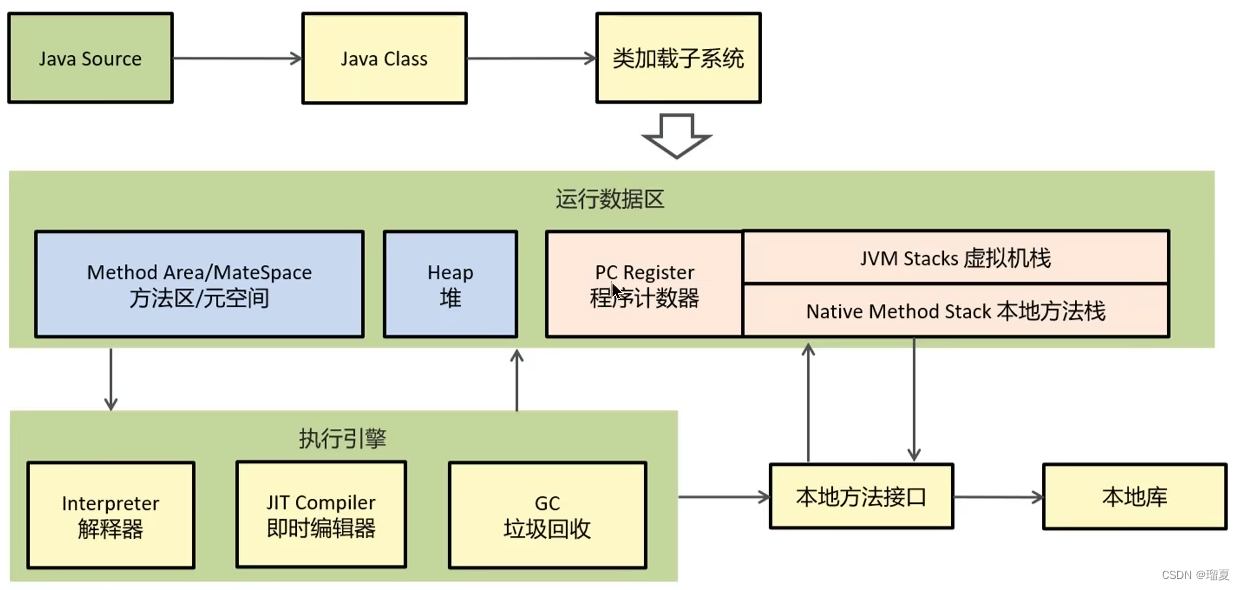
- Class loader: Loads bytecode into memory.
- Runtime data area: JVM memory where programs run.
- Execution engine: Translates bytecode to native instructions.
- Native method interface: Interacts with native libraries.
3.2 Runtime data areas
- Method area / Metaspace: Thread-shared; stores class info, constants, static variables. Throws
OutOfMemoryError: Metaspace. - Heap: Thread-shared; stores objects and arrays. Throws
OutOfMemoryError. Divided into young generation (Eden, two Survivor) and old generation. - Program counter: Thread-private; stores current bytecode instruction address.
- JVM stack: Thread-private; creates stack frames for methods (local variables, operands, return address). Throws
StackOverflowErrorif depth too deep,OutOfMemoryErrorif can't expand. - Native method stack: For native methods.
3.3 Does garbage collection involve stack?
GC primarily works on heap; stack frames are freed when method exits.
3.4 Is larger stack memory always better?
Default 1MB. Not necessarily; fixed machine memory means fewer active frames with larger stack, potentially reducing efficiency.
3.5 Are local variables inside a method thread-safe?
If they don't escape method scope, yes. If they reference an object that escapes, it may be unsafe.
3.6 When does stack overflow occur?
- Too many stack frames (e.g., deep recursion).
- Too large stack frames (rare).
3.7 Differences between heap and stack?
- Content: Heap stores objects and arrays (focus on data storage). Stack stores local variables, stack frames, operands (focus on method execution).
- Visibility: Heap is thread-shared; stack is thread-private.
- Errors: Stack:
StackOverflowError,OutOfMemoryError; Heap:OutOfMemoryError. - Physical address: Heap may be non-contiguous (slower, GC works here), stack is contiguous (LIFO, faster).
- Memory allocation: Heap allocated at runtime, size variable; stack size fixed at compile time.
3.8 What is runtime constant pool? Difference with string constant pool?
- Runtime constant pool: Part of method area; stores literals and symbolic references from class files; loaded when class is loaded.
- String constant pool: Stored on heap; implemented as a C++ hash table; stores string literals as keys and references to String objects as values.
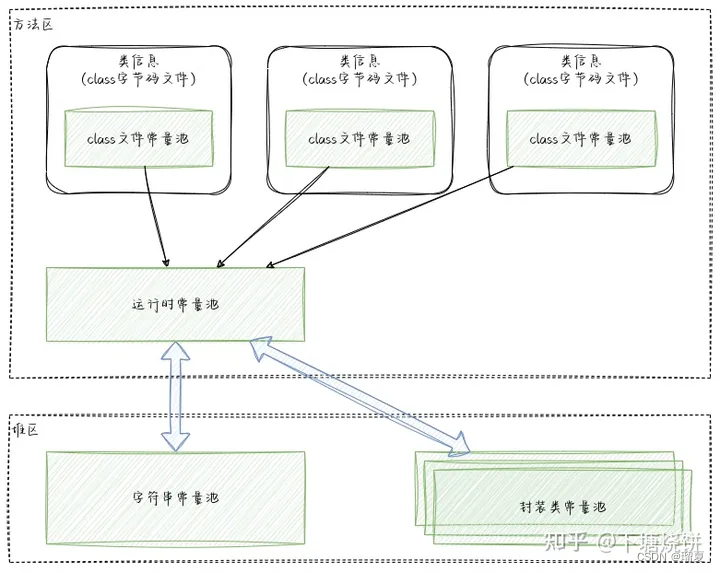
3.9 What is direct memory?
- Not part of JVM memory; OS memory.
- Common in NIO for data buffers; high performance, not affected by JVM GC.
- BIO: blocking IO; thread blocks until data returned.
- NIO: non-blocking IO; thread polls sockets.
- AIO: asynchronous non-blocking IO; OS handles read, notifies client.
3.10 When can an object be garbage collected? How to mark?
When no strong references point to it.
Reachability analysis:
- GC roots: objects referenced in JVM stacks, native method stacks, static fields/constants in method area.
- Traverse from roots; unreachable objects are garbage.
Reference counting: Each object has a counter; when zero, it's garbage (not used in mainstream JVMs due to circular reference issues).
3.11 Garbage collection algorithms
-
Mark-Sweep:
- Mark: traverse and mark garbage.
- Sweep: free marked memory.
- Disadvantages: two passes, slow; memory fragmentation.
-
Mark-Compact:
- Mark: same.
- Compact: move live objects to one end.
- Sweep: free remaining space.
- Disadvantages: slow.
-
Copy:
- Divide memory into two equal halves; use one half; when GC, copy live objects to the other half, then clear the first half.
- Disadvantage: low memory utilization.
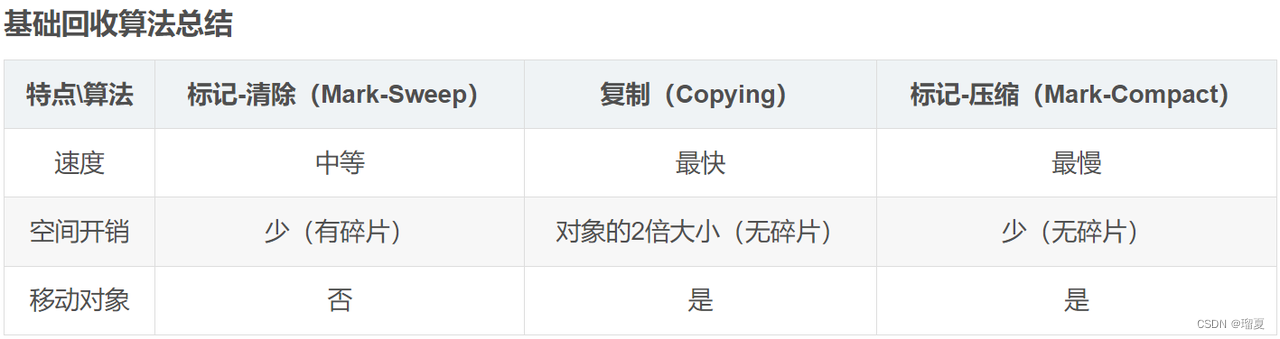
3.12 Generational collection algorithm
In Java 8, heap is divided into young and old generations.
- Young generation uses copy algorithm.
- Old generation uses mark-compact algorithm.
- Objects promoted after surviving multiple minor GCs.
Large objects go directly to old generation (controlled by -XX:PretenureSizeThreshold, works only with Serial/ParNew).
Long-lived objects: Age counter in object header; after each minor GC, if survives and fits in survivor, age increments; default threshold 15.
Dynamic age judgment: If total size of live objects in survivor > 50% of survivor size (configurable), objects with age >= current are moved to old generation.

Minor GC vs Full GC:
- Minor GC: young generation only; frequent, fast.
- Full GC: old generation; often accompanied by Minor GC; 10x slower.
3.13 Garbage collectors
- Serial: Single thread; STW.
- Parallel: Multiple threads; STW; default in many JVMs.
- CMS: Concurrent; low pause; uses mark-sweep; no compaction.
- G1: Region-based; for large heaps; high throughput and low pause.
3.14 G1 garbage collector
- Default in JDK9; replaces CMS.
- Divides heap into regions (Eden, Survivor, Old, Humongous).
- Phases:
- Initial mark: mark GC roots directly (STW).
- Concurrent mark: traverse from roots (STW? Actually concurrent).
- Remark: fix missed marks (STW).
- Mixed collection: collect regions with highest garbage (survivor objects go to new survivor; old objects to new old). Pause time target decides region selection.
3.15 What are class loaders? Types?
Class loaders load .class files into JVM.
Built-in:
- Bootstrap ClassLoader: C++ implementation; loads core libraries (
JAVA_HOME/lib). - Extension ClassLoader: loads
JAVA_HOME/lib/ext. - Application ClassLoader: loads classes on classpath (user code).
Custom class loaders can be created by extending ClassLoader.
3.16 Parent delegation model? Why use it?
When a class loader tries to load a class, it delegates to its parent first; only if parent fails does it attempt to load itself.
Reasons:
- Prevents duplicate loading.
- Security: prevents tampering with core APIs.
- Ensures class uniqueness.
3.17 Class loading process?
- Loading: Get binary stream by fully qualified name; parse into method area data structure; create
Classobject on heap. - Verification: Verify file format, metadata, bytecode, symbol references.
- Preparation: Allocate memory for static variables and set default values (zero).
- Resolution: Replace symbolic references with direct references.
- Initialization: Execute static initializers and static field assignments.
- Usage: Execute code.
- Unloading: Destroy
Classobject.
3.18 JVM tuning parameters
-Xms 512m: Initial heap size.-Xmx 1g: Max heap size.-Xss 256k: Stack size (default 1M).-XX:SurvivorRatio=8: Eden:Survivor ratio = 8:2.-XX:MaxTenuringThreshold=10: Age threshold for promotion (default 15).-XX:+Use[GCName]: Select garbage collector.
3.19 JVM tuning tools
jps: Process status.jstack: Thread stack info.jmap: Heap info (size, usage).jstat: Garbage collection info.jconsole: Visual monitoring.VisualVM: Memory, threads, classes.
3.20 How to diagnose memory leak?
- Get dump file via
jmapor JVM parameters. - Analyze with
VisualVM. - Locate the problematic code and fix.
3.21 How to diagnose high CPU usage?
- Use
topto find high CPU process. - Use
ps H -eo pid,tid,%cpu | grep <pid>to find high CPU threads. - Use
jstackto examine thread stack; locate code issue.
4. MySQL
4.1 InnoDB vs MyISAM characteristics and usage
| Feature | InnoDB | MyISAM |
|---|---|---|
| Transactions | Yes | No |
| Foreign keys | Yes | No |
| Locks | Row & table | Table only |
| Full-text index | No | Yes |
Usage: InnoDB for high concurrency/transactions; MyISAM for read-heavy, write-light scenarios without transactions.
4.2 How to prevent SQL injection?
Use parameterized queries (e.g., #{} in MyBatis) instead of concatenating values into SQL.
4.3 How to achieve idempotency?
- Unique index (primary key).
- Optimistic lock (version field).
- Token + Redis: Token generated by server, validated before operation.
4.4 Execution flow of a SQL statement
MySQL has server layer and storage engine layer.
- Connection: Connector verifies credentials and permissions.
- Query cache (if query): Check cache; if hit, return directly.
- Parser: Lexical and syntax analysis.
- Optimizer: Optimize query.
- Executor: Check permissions, call storage engine.
4.5 Transaction properties (ACID)
- Atomicity: All or nothing; via
undo log. - Consistency: Transition from one consistent state to another; via
undo log. - Durability: Committed changes persist; via
redo log. - Isolation: Transactions don't interfere; via locking.
4.6 Isolation levels, dirty read, non-repeatable read, phantom read
- Dirty read: Read uncommitted data.
- Non-repeatable read: Same query returns different results (due to updates).
- Phantom read: Insert/delete causes rows to appear/disappear unexpectedly.
Isolation levels (low to high):
- Read Uncommitted: Allows dirty reads.
- Read Committed: Prevents dirty reads.
- Repeatable Read: Prevents dirty and non-repeatable reads; default in MySQL; phantom reads possible.
- Serializable: Prevents all.
4.7 Types of locks: row, table, shared, exclusive
| Type | Deadlock | Concurrency | Usage |
|---|---|---|---|
| Table | No | Low | Read-many or write-many scenarios |
| Row | Yes | High | High concurrency |
| Page | Yes | Medium |
Row locks (InnoDB only):
- Shared (S) lock: Allows reading; prevents other transactions from acquiring exclusive lock.
- Exclusive (X) lock: Allows writing; prevents both S and X locks.
Intention locks: Automatic; acquired before S or X on table.
4.8 Inner join, left join, right join, full join
- Inner join: Only rows that match in both tables.
- Left join: All rows from left table; matching rows from right; NULL if no match.
- Right join: All rows from right table; matching from left.
- Full join: Union of left and right.
4.9 Indexes and their types
Index: like a book's table of contents; sorts values for quick lookup.
Types:
- Normal index: Basic index.
- Primary key index: Unique, non-null.
- Composite index: Multiple columns.
- Unique index: Ensures uniqueness.
- Foreign key index: For foreign keys.
- Full-text index: For full-text search.
4.10 Advantages, disadvantages, and usage rules of indexes
Advantages:
- Faster queries.
- Reduced time for sorting and grouping.
- Accelerated table joins.
- Uniqueness guarantee.
Disadvantages:
- Occupies disk space.
- Slows down DML operations (insert, update, delete) due to index maintenance.
When to avoid indexes:
- Columns rarely used in queries.
- Columns with few distinct values.
- Columns with much more writes than reads.
Rules:
- Index columns with high query frequency.
- Index columns used in sorting, grouping, joins.
- Prefer unique indexes.
- Prefer shorter indexes.
- Limit number of indexes per table.
4.11 Index principle: B+ tree advantages
B-tree: Each node stores keys and data; multiple children. Reduces disk I/O.
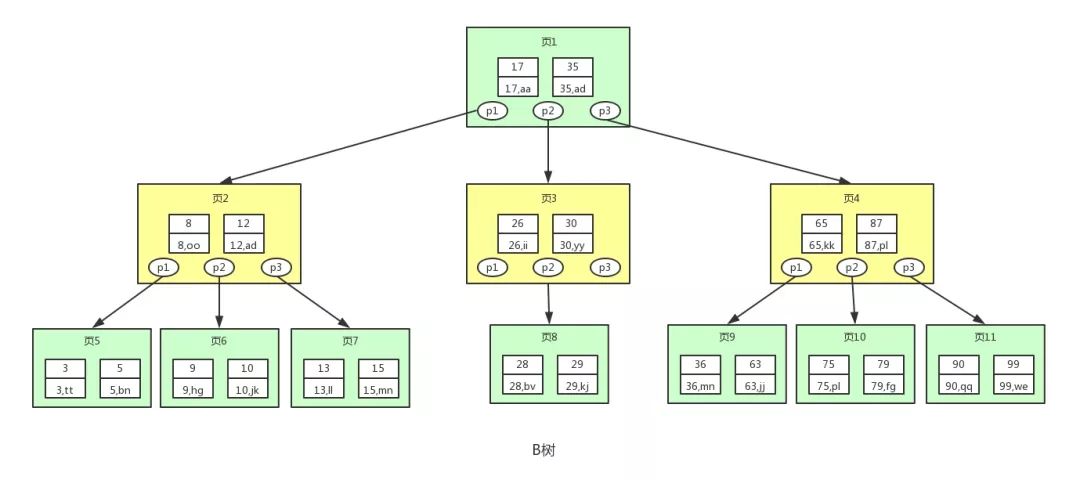
B+ tree: Internal nodes store only keys; data stored only in leaf nodes. Leaves are connected by linked list.
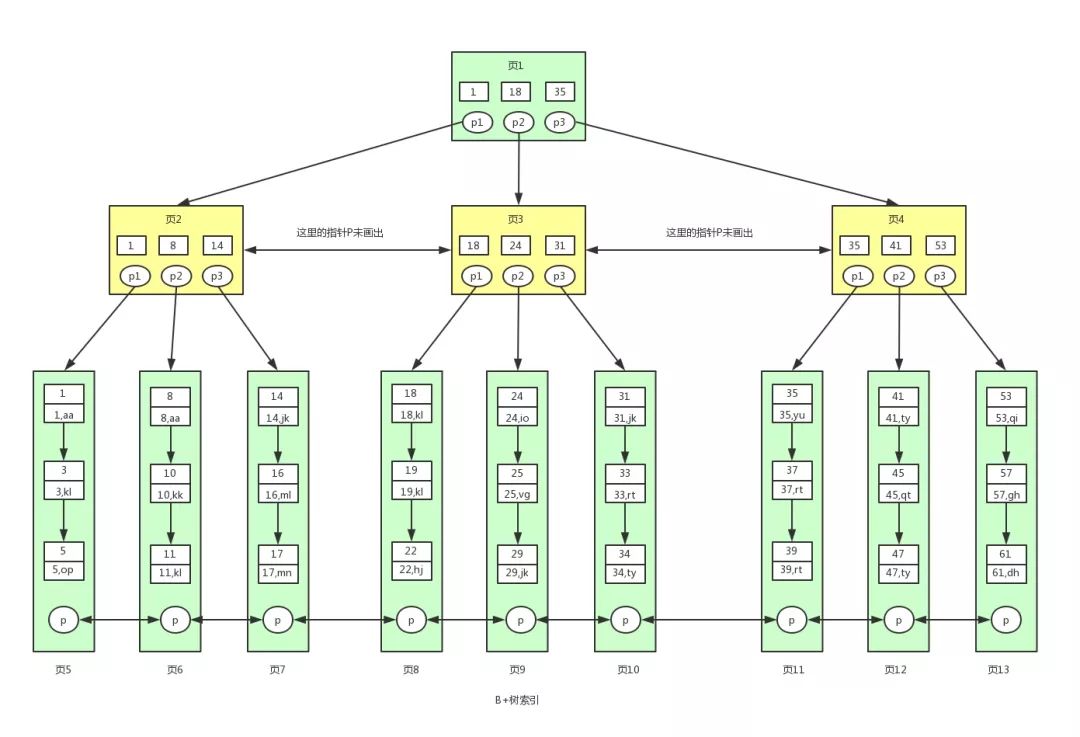
Advantages of B+ over B-tree:
- Non-leaf nodes store more keys (higher fan-out) due to no data, reducing tree height and I/O.
- Range queries, sorting, grouping are faster because leaves are linked.
- Insert/delete faster due to less data movement.
In InnoDB, B+ tree index uses primary key as the key for clustered index; non-clustered indexes store primary key and require a second lookup ("back to table"). In MyISAM, leaves store data file address.
4.12 Clustered vs non-clustered index
- Clustered index: B+ tree built on primary key; leaves store full row data.
- Non-clustered index: Built on non-primary-key columns; leaves store primary key value. Querying requires second lookup using primary key ("back to table").
4.13 Composite index principle
Composite index indexes multiple columns. B+ tree sorts by first column, then second, etc. Follows leftmost prefix rule.
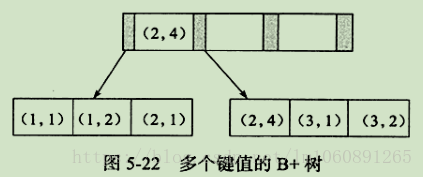
Leftmost prefix: Query must use columns starting from the leftmost; otherwise index may not be used.
4.14 When does index become invalid?
- Using
LIKEwith%at start. - Using
ORwithout all conditions indexed. - Violating leftmost prefix rule.
- Implicit type conversion (e.g., varchar column compared to int).
- Using functions or calculations on indexed column.
ORDER BYnot matching index order.- Full table scan faster.
- Using parameters in
WHERE.
4.15 High-performance database optimization best practices
- Denormalization: Add redundant fields for query speed; ensure consistency via same transaction.
- Business-level constraints: Avoid database foreign keys.
- Extensible fields: Use JSON for flexible schemas; consider virtual columns for indexing key fields.
- Hot-cold separation: Split frequently-updated and rarely-updated fields into different tables.
- Service partitioning: Choose shard keys to allow local transactions, avoiding distributed transactions.
- Single-table queries: Prefer joins only when necessary; easier for future sharding.
4.16 GROUP BY usage
GROUP BY groups rows with same values in specified columns; selected columns must be in GROUP BY or aggregate functions.
Example: SELECT category, SUM(score) FROM grades GROUP BY category ORDER BY SUM(score) DESC.
4.17 SQL writing order
SELECT <columns>
FROM <table>
JOIN <table> ON <condition>
WHERE <condition>
GROUP BY <columns>
HAVING <condition>
UNION
ORDER BY <columns>
LIMIT <number>;
4.18 JOIN vs UNION
JOIN: Combines columns from two tables based on a condition.UNION: Combines rows from multipleSELECTqueries;UNION ALLincludes duplicates.
5. Redis
5.1 Cache penetration, cache breakdown, cache avalanche and solutions
Cache penetration: Requests for non-existent data bypass cache and hit database.
Solutions:
- Cache empty object: Store null in cache for missing keys.
- Bloom filter: Check key existence before cache query.
Cache breakdown: A hot key expires, causing many requests to hit database.
Solutions:
- Distributed mutex lock: Only one thread rebuilds cache; others wait.
- Never expire: Store logical expiry in value; asynchronously refresh.
Cache avalanche: Many keys expire simultaneously or Redis goes down.
Solutions:
- Random TTL: Add random jitter to expiry.
- Never expire + distributed lock.
- Redis cluster for high availability.
- Rate limiting / circuit breaker.
- Multi-level cache.
5.2 Five data types of Redis
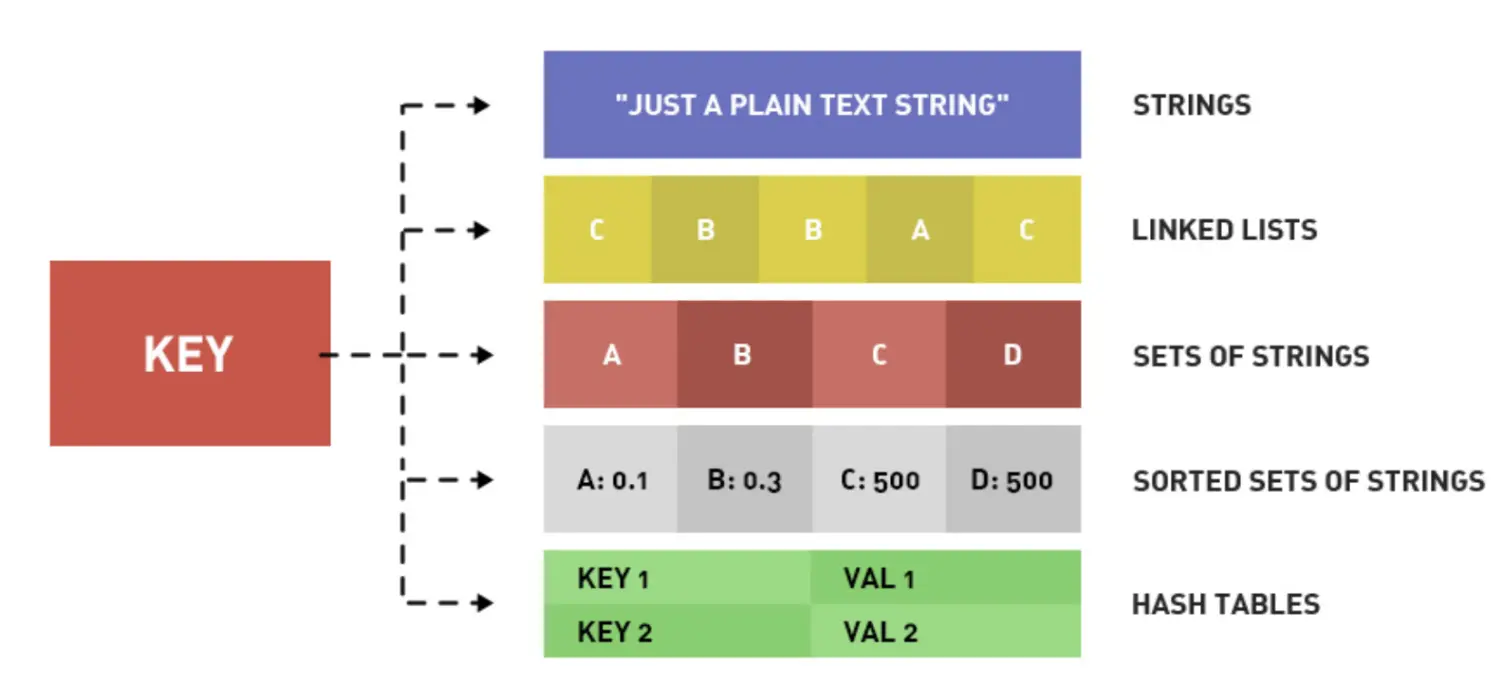

5.3 Best practices for Redis
Key design:
- Format:
business:data:id(e.g.,login:user:1). - Brief: < 44 bytes (to use
embstrencoding). - No special characters.
Big key: Large size or many members. Hazards:
- Network congestion.
- Data skew.
- Redis blocking on operations.
- CPU spike on serialization.
Summary:
- Small keys ( < 44 bytes).
- Split big keys.
- Use appropriate data structures.
- Hash with ≤ 500 entries.
- Set reasonable TTL.
Update strategy:
- Delete cache rather than update; avoid invalid updates.
- Update database first, then delete cache (safer).
5.4 Why is Redis fast?
- In-memory: No disk I/O.
- Efficient data structures: Hash table O(1), skip list O(log N).
- Single-threaded: No context switching or lock contention.
- I/O multiplexing + event handlers (epoll).
- Virtual memory: Swap cold data to disk.
I/O multiplexing: Single event loop monitors multiple sockets; non-blocking.
Command execution: Parse, execute, reply.
5.5 Why is Redis single-threaded?
Performance bottleneck is memory and network, not CPU. Single thread avoids thread safety and context switching. Since Redis 6.0, multi-threading used for network I/O.
5.6 How to ensure dual-write consistency with database?
- Strong consistency: Use
Redissonread-write lock (e.g., for coupon stock). - Eventual consistency: Write to DB first, then asynchronously update cache via MQ or Canal.
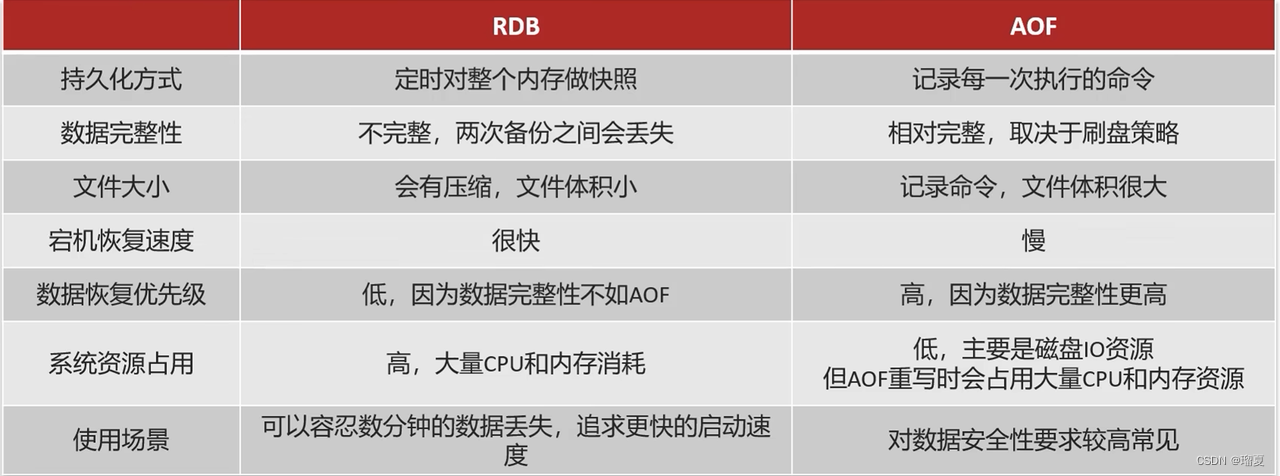
5.7 Persistence methods
Redis forks a child process to persist data.
- RDB: Point-in-time snapshots; configured via
saveparameters. - AOF: Appends every write command; similar to MySQL binlog.
If both enabled, AOF takes precedence on restart.
5.8 Expiry deletion strategy
- Lazy deletion: Check key expiry on access; delete if expired.
- Periodic deletion: Periodically check a subset of keys.
No automatic timer due to CPU waste.
5.9 Eviction policies
8 policies total:
-
noeviction,allkeys-lru,allkeys-lfu,volatile-lru,volatile-lfu,allkeys-random,volatile-random,volatile-ttl. -
Use LRU if access patterns vary (hot/cold data).
-
Use
volatile-*to protect sticky data (no TTL). -
Use LFU for frequent short-term access.
Scenario: 10M data in DB, Redis holds only 200k – use LRU.
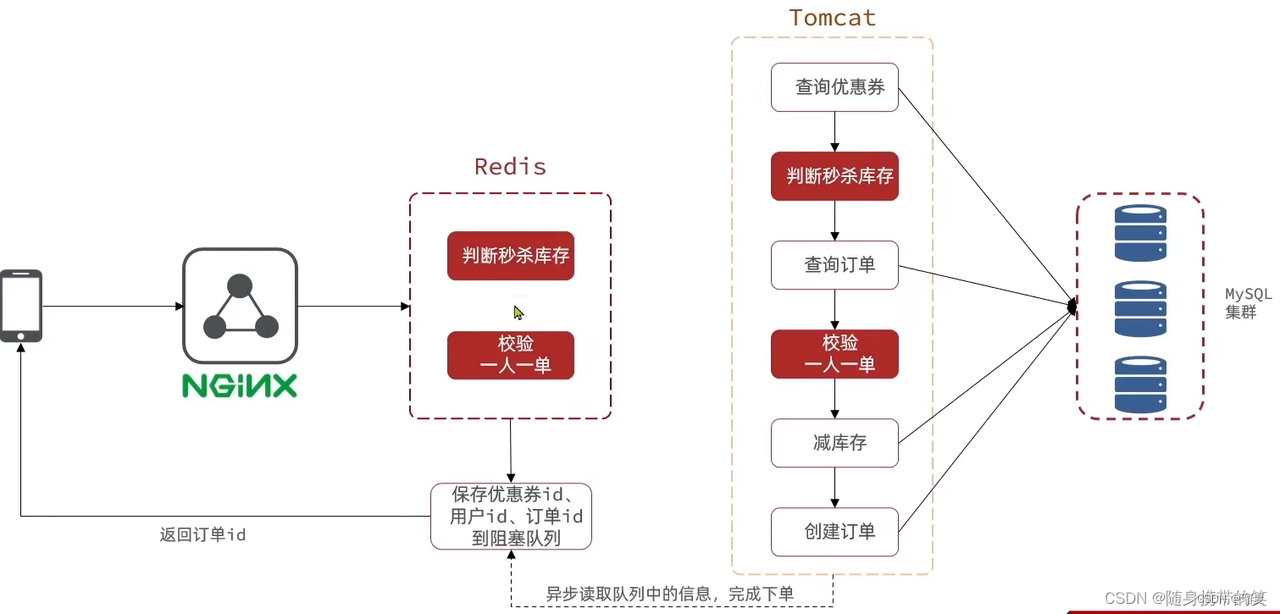
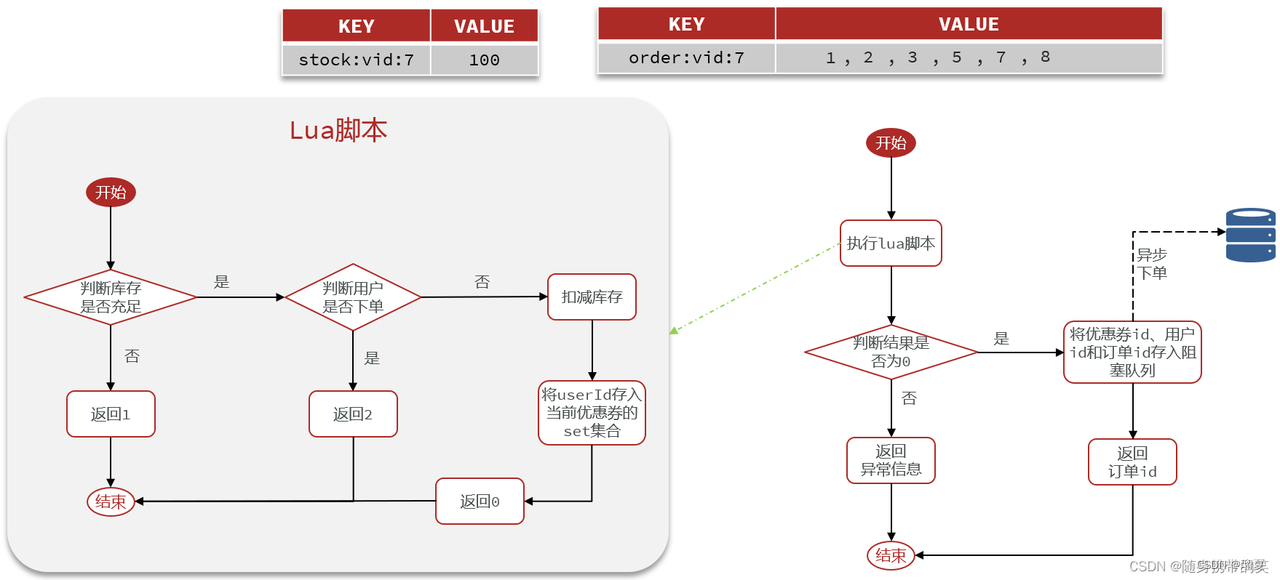
5.10 Redis usage in projects
Flash sale logic:
- Store coupon stock (string) and order set (set) in Redis.
- Check stock > 0 for user.
- Check if user already in order set; if not, decrement stock and add user.
- All done in Lua script for atomicity.
- After eligibility, async order generation via Kafka; return order ID.
- Use
Redissionlockorder:user:{userId}for safety.
5.11 Principle of Redission distributed lock
- Based on Redis hash: key = lock name, field = client ID (UUID+thread ID), value = reentrant count.
- Lock: Lua script: if key not exists, set and return null; if exists and field same, increment; else return TTL.
- Renewal: Watchdog thread renews lease every
leaseTime/3(default 30s). - Unlock: Decrement reentry count; if 0, delete key and notify.
- RedLock: To avoid single point failure, lock on multiple Redis instances; success if majority succeed.
5.12 Master-slave replication principle
- Slave sends sync request.
- If first connecsion, full sync: send RDB + buffered commands.
- Later incremental sync: send commands from replication log.
Full sync:
- Master runs
bgsave, sends RDB. - Master buffers write commands in
repl_back.log. - After RDB, send buffered commands.
Incremental sync:
- Master reads from offset in replication log.
5.13 High availability: Sentinel, split-brain
Sentinel:
- Monitors instances every second; marks as objective down if quorum agrees.
- Performs failover: promotes a slave to master.
- Notifies clients.
Split-brain:
- Master temporarily disconnected; Sentinel promotes new master; old master continues accepting writes.
- When old master reconnects, it becomes slave and discards data.
Solution: Configure min-slaves-to-write and min-slaves-max-lag to reject writes if not enough slaves.
5.14 Redis sharded cluster: purpose and principle
Characteristics:
- Multiple master nodes (high write capacity).
- Each master has slaves (high read capacity).
- Masters ping each other for health.
- Requests routed to correct node.
Hash slots: 16384 slots assigned to masters. Compute CRC16(key) % 16384 to determine target node.
6. Spring
6.1 Understanding of Spring
Spring is an open-source lightweight Java framework centered on IoC (Inversion of Control) and AOP (Aspect-Oriented Programming). It provides Spring MVC, Spring JDBC, transaction management, and integrates many third-party frameworks.
6.2 Spring features
- Lightweight.
- IoC.
- AOP.
- Declarative transactions.
- Container: manages bean lifecycle.
- Integration with various frameworks.
6.3 Understanding IoC
IoC (Inversion of Control) is a design principle where object creation and management are transferred from application code to the Spring container. This decouples modules and improves maintainability.
6.4 Dependency Injection (DI) methods
- Setter injection.
- Constructor injection.
- Autowiring.
6.5 What is AOP? Application scenarios?
AOP (Aspect-Oriented Programming) separates cross-cutting concerns (logging, security, transactions) from business logic, reducing duplication and improving maintenance.
Concepts:
- Target: Proxied object.
- Aspect: Combination of pointcut and advice.
- Join point: Method to be enhanced.
- Pointcut: Set of join points.
- Advice: Enhancement logic.
- Weaving: Process of applying advice.
Scenarios:
- Logging.
- Caching.
- Declarative transactions.
- Exception handling.
6.6 AOP principle: JDK dynamic proxy vs CGLIB
- JDK dynamic proxy: Used if target implements interface; creates proxy using
InvocationHandlerandProxy.newProxyInstance. - CGLIB proxy: Used if target does not implement interface; creates subclass.
Difference from static proxy:
- Static proxy defined at compile time; dynamic at runtime.
- Static proxy requires one class per target; dynamic proxy can handle many targets.
6.7 When does Spring transaction fail?
- Same class method calling transactional method (no proxy).
- Method not
public. - Method
finalorstatic. - Database engine doesn't support transactions (e.g., MyISAM).
- Exception caught and not thrown.
- Exception type not matching
rollbackFor(defaultRuntimeException). - Propagation behavior like
NEVERorNOT_SUPPORTED.
6.8 Are Spring beans thread-safe?
Not inherently thread-safe. If bean has mutable member variables, use synchronization or @Scope("prototype").
7. Computer Networks
7.1 TCP three-way handshake, four-way wave
Three-way handshake:
- Client sends SYN with seq=x.
- Server replies SYN+ACK with ack=x+1, seq=y.
- Client sends ACK with ack=y+1.
Four-way wave:
- Client sends FIN with seq=x.
- Server replies ACK with ack=x+1, seq=y.
- Server sends FIN with seq=z.
- Client replies ACK with ack=z+1, seq=x+1.
7.2 HTTPS and its principle
HTTPS = HTTP + SSL/TLS. Uses encryption and digital certificates to secure data transmission.
8. Data Structures and Algorithms
(Content not provided in original)
9. Others
9.1 Cross-origin issues and solutions?
Cross-origin is caused by browser's same-origin policy (protocol, host, port must match).
Solutions:
- JSONP (using
<script>tag). - Set response header
Access-Control-Allow-Origin: *. - NGINX proxy (browser to NGINX, NGINX to target).
